
怎么才能在35岁之前存够100万?
资源下载 https://wwbgk.lanzn.com/iD1ht3zipoab 解压密码:jubt
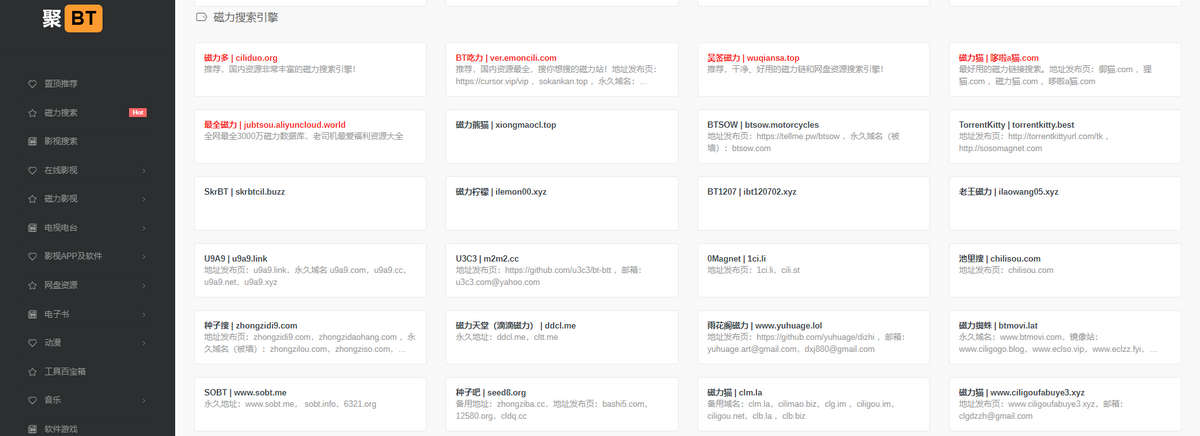
聚BT论坛:https://bbs.jubt.top 聚BT最新地址:https://jubt....

汇总一下提供全球新闻、市场和地缘政治事件的实时仪表盘类工具,方便跟踪当下的伊朗等...
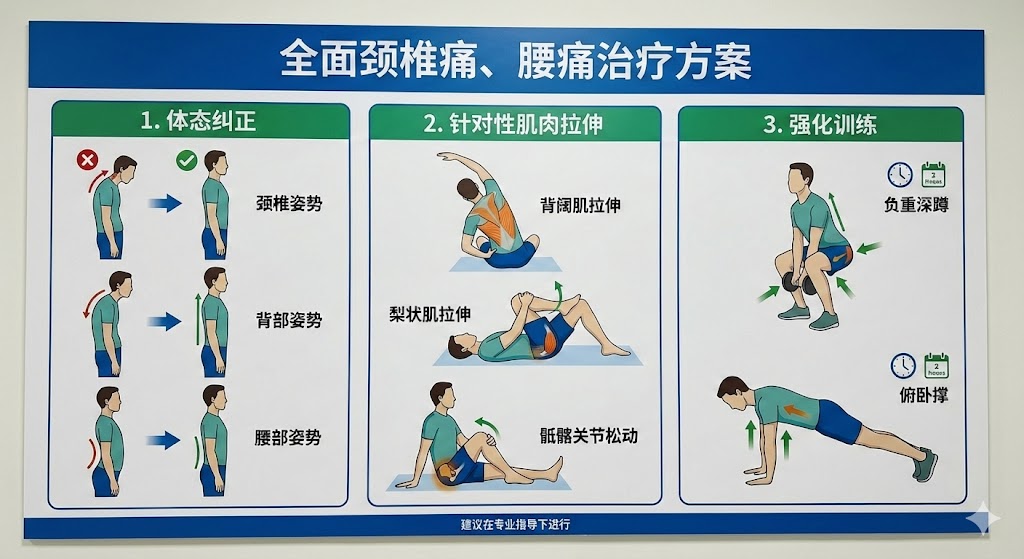
作为重度颈椎/腰椎患者已经10多年了,颈椎痛/腰痛严重影响了生活、工作、睡眠质量,因此在此过程...
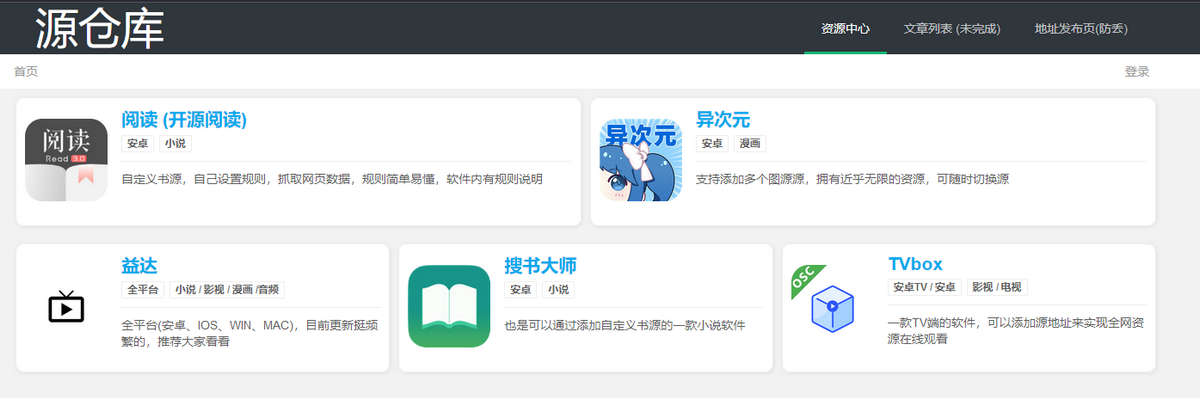
汇总一下常用的书源、直播源、漫画源,会持续更新维护 1、书源 1.1、书源 源仓库 https...

Z-Access,Z-library的多途径访问方式 为了避免失联,Z-library 官方单...

收录免费电子书下载站、免费电子书APP,此帖会长期维护更新。 名称 简介 网址 Op...
资源下载 https://wwbgk.lanzn.com/iD1ht3zipoab 解压密码:jubt

使用 VPN/代理 之后,你可能认为网站已经无法判断自己的真实位置。 实际上,VPN/代理 通常只改变公网 IP。浏览器依然可能通过 Geolocation API、系统时区、语言区域、WebRTC 和其他环境信息,获得与你的 VPN ...

软件资源 CyVisGuard https://github.com/flankerhqd/cyvisguard 开源 AI Agent 安全控制网关,专门用来保护会调用工具、持有凭据的 AI Agent。处于 Agent 与外部资源之...
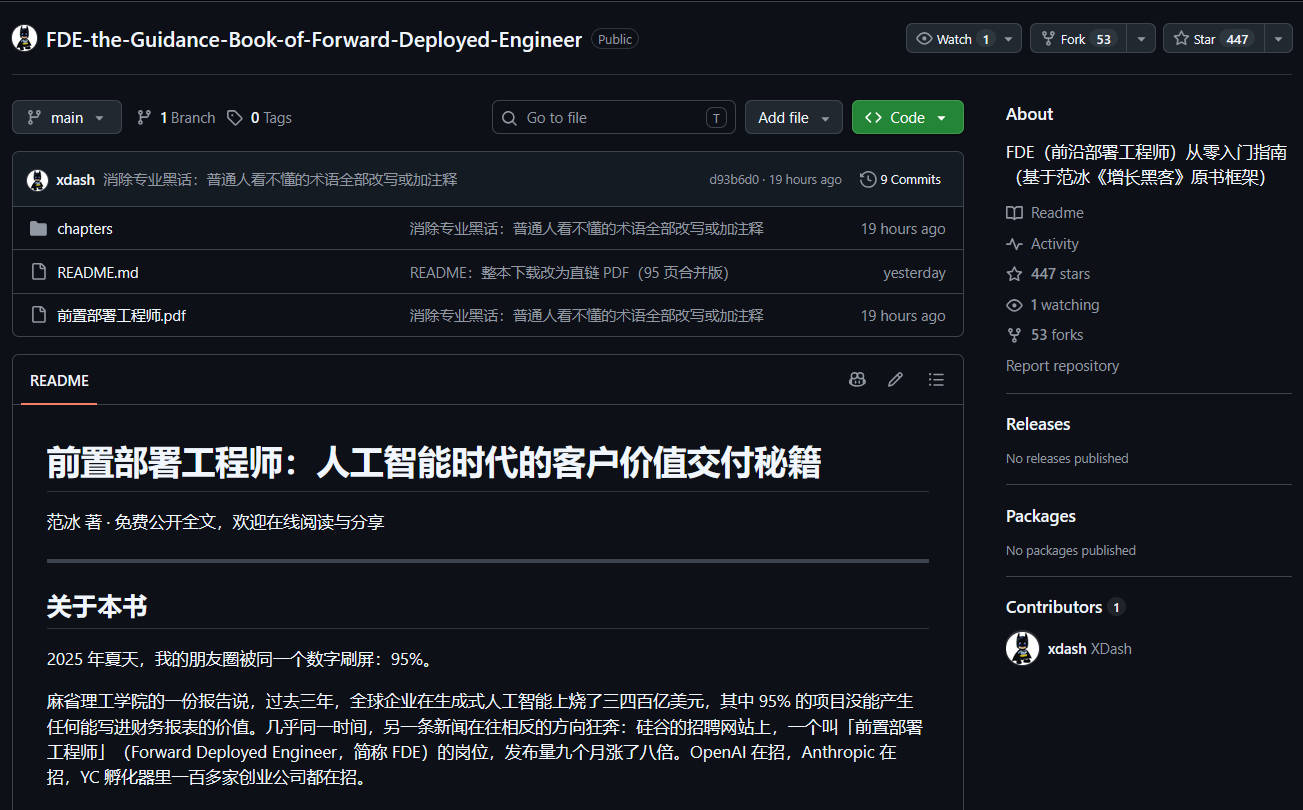
文档地址:https://github.com/xdash/FDE-the-Guidance-Book-of-Forward-Deployed-Engineer 更多优质文档资源 ...

资源下载 https://wwbgk.lanzn.com/iR7FA3zcdpxc 解压密码:jubt
SkrBT、磁力柠檬 、BT1207 、老王磁力 、吴签磁力、磁力熊猫 这几个磁力搜索站的风格都类似,资源丰富,算是目前磁力搜索引擎比较好用的,值得推荐给各位老司机。 吴签磁力:https://wuqiansa.top SkrBT:ht...
文档地址:https://saduck.top/ 更多优质文档资源
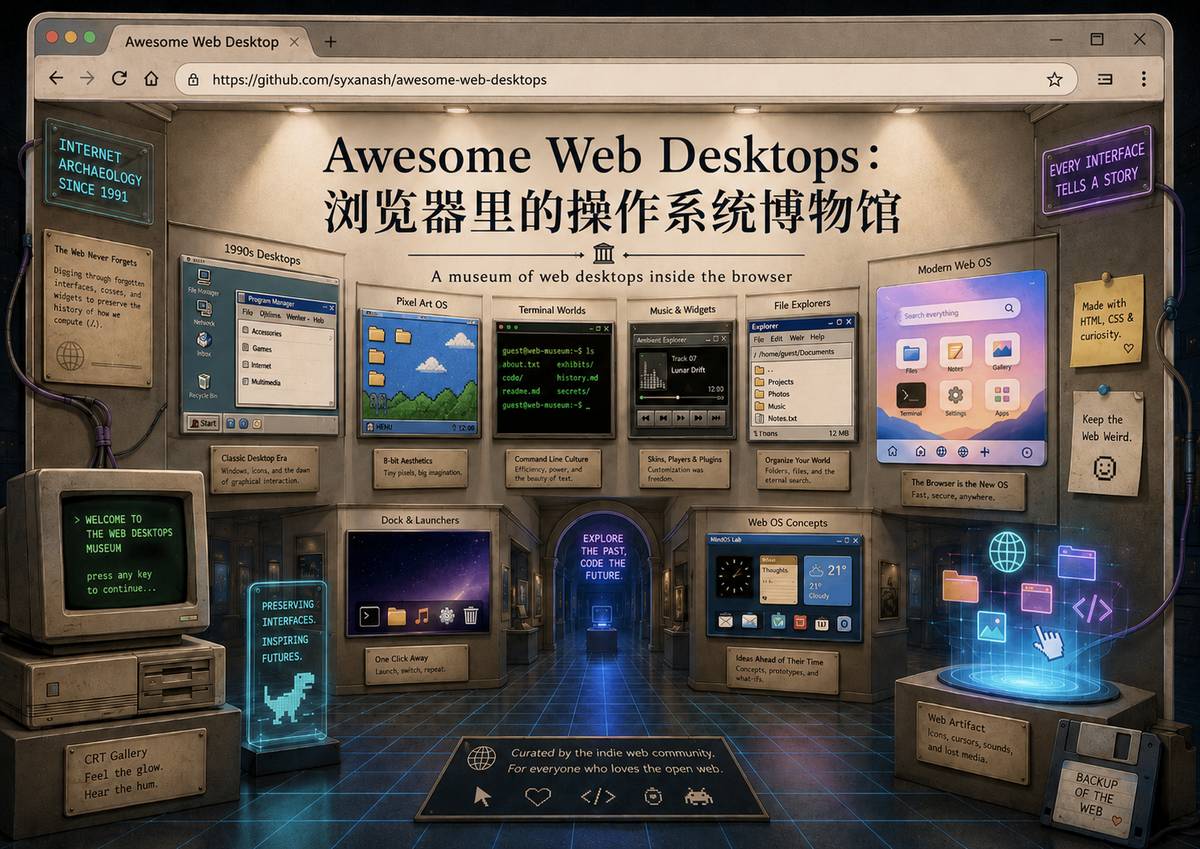
如果你偏爱 Windows 95/98/XP 或 Classic Mac OS 等老式操作系统的设计,应该对这类像素风或拟物风的“网页版操作系统”并不陌生。 互联网上一直存在着一群复古极客,致力于把操作系统搬进浏览器: 复刻经典:从 W...

软件资源 TurboFieldfare https://github.com/drumih/turbo-fieldfare 在 2 GB 内存 M 系列 MacBook 上跑Gemma 4 26B-A4B 推理模型 &nb...

资源下载 https://wwbgk.lanzn.com/iWE523z5a2ub 解压密码:jubt