吴签磁力、SkrBT、磁力柠檬、老王磁力、BT1207、磁力熊猫系列站,干净、好用的磁力搜索引擎!
admin 5小时前
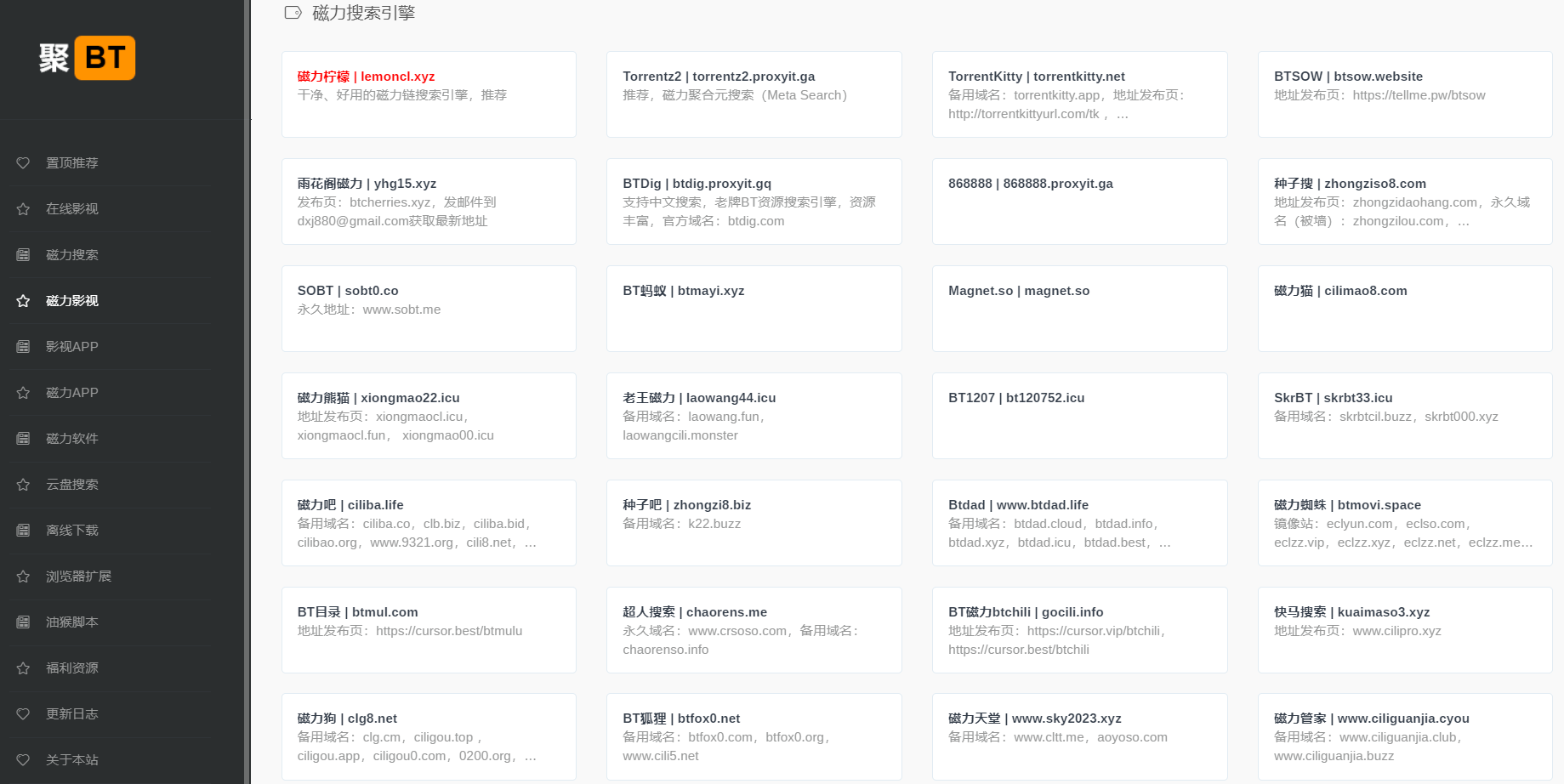
SkrBT、磁力柠檬 、BT1207 、老王磁力 、吴签磁力、磁力熊猫 这几个磁力搜索站的风格都类似,无广告、资源丰富,值得推荐给各位老司机。 吴签磁力:https://wuqiansa.top/?_jubt SkrBT:https://skrbtc...

浏览诸如WSJ、Bloomberg、财新等网站,会遇到付费会员才能观看的文章,或者是免费浏览几...

深受喜爱的Z-library 域名今天被United States Postal Inspec...

更多网盘资源资源,请参考:网盘资源分享站 或 聚BT导航 名称 简介...

ASMR(英语:Autonomous sensory meridian response,缩写...

收录免费电子书下载站、免费电子书APP,此帖会长期维护更新。 名称 简介 网址 Z-...
聚BT浏览器扩展:聚合最优秀的资源,赋能个性化垂直搜索,一键搜索上百个资源站 聚BT论坛:htt...
admin 5小时前
SkrBT、磁力柠檬 、BT1207 、老王磁力 、吴签磁力、磁力熊猫 这几个磁力搜索站的风格都类似,无广告、资源丰富,值得推荐给各位老司机。 吴签磁力:https://wuqiansa.top/?_jubt SkrBT:https://skrbtc...
admin 8小时前
一个朋友(原免费机场)是一个免费机场推荐网站。涵盖了各种类型的免费节点、机场、加速器资源。收录了各种机场价格折扣、促销活动以及免费试用。 由于资源还比较丰富且更新及时,收录的机场、节点、加速器质量都还不错,因此理论上可以持续白嫖,不用再东奔西走找各种...
admin 8小时前
软件资源 Workers AI LLM Playground https://playground.ai.cloudflare.com/ Cloudflare提供的AI LLM体验平台,基于Cloudflare Workers AI 部...
admin 8小时前
文档地址:https://cq3vh0u6poj.feishu.cn/wiki/OXfHwK3KyiR6FekMkXAcqA7AnCe 更多精品文档资源 转载请注明:出家如初,成佛有余 » 人工智能专业答疑问题...
admin 1天前
汇总了各种工程施工规范 文档地址:https://www.kdocs.cn/l/ch9cGMpgdXxG 更多精品文档资源 转载请注明:出家如初,成佛有余 » 工程图集大全
admin 1天前
软件资源 中国风水在线测算工具 https://chinesefengshui.net/zh 提供结合AI智能分析的中国风水在线测算工具,包括中国风水测算、易经占卜、生辰八字算命等服务 Awesome Chinese LLM https...
admin 1天前
低端游戏 是一个支持在网页里直接玩老的 DOS/Windows 游戏的服务,目前支持在线玩星际、暗黑、红警 Windows 版、古墓丽影 2 和 3 、极品飞车 2se 、最终幻想 7 、大富翁 4 等260多款经典DOS/Window...
admin 2天前
速特生活是一个支持磁力搜索极速播放的APP,提供极速精准的搜索体验,增加诸多便捷浏览器辅助工具、提供大空间不限速网盘服务、实用工具导航等诸多功能。 速特生活值得推荐的一些功能特色: – 多端支持,同时支持iOS和Androi...
admin 2天前
Windows 10和Windows 11都缺省安装了一些应用,包括News、Teams、Xbox、Office Hub、Feedback Hub等等,有些应用还安装为系统服务,缺省会随系统启动,导致系统臃肿、缓慢。另外还对TPM等有硬件有要求,对老...
admin 2天前
收集了248本恋爱书籍 文档地址:https://github.com/apachecn/loving-books 更多精品文档资源 转载请注明:出家如初,成佛有余 » 恋爱指南书籍